

Data Integration Solutions – If your organisation collects data from apps, databases, cloud services, devices or partners, you need a reliable way to bring those pieces together so analytics, ML, dashboards and apps can work. That’s where data integration solutions come in: they move, transform, sync, and govern data so teams can trust a single source of truth. https://www.ibm.com/think/topics/data-integration
What is data integration?
Data integration is the set of processes and tools that combine data from different sources into a unified view. That may mean copying data into a central store (data warehouse or lake), streaming changes between systems, or creating a virtual layer that joins data on demand. The goal: accurate, timely, and governed data that people and systems can use.
Why it matters — three simple examples
- Marketing needs reliable campaign funnels — but data sits in ad platforms, CRM and an event database. Integration stitches these sources into one analytics-ready set.
- Finance needs the month-end close to be fast and accurate — integrations automate ingestion from ERP, payroll, and bank feeds, reducing manual reconciliations.
- Product teams need event-level telemetry to build ML features — streaming integrations (CDC or event pipelines) feed real-time models.
When integration is done right, teams move faster, decisions are better, and cost/effort fall.
Core types of data integration (what each does best)
Below is a practical comparison table of the common solution types you’ll encounter.
| Integration type | What it does | When to use it | Main pro | Main con |
| ETL (Extract, Transform, Load) | Extracts from sources, transforms data in a pipeline, loads to a data store | When you need processed, analytics-ready datasets in a warehouse | Mature patterns, strong data quality controls | Can be slower for real-time needs |
| ELT (Extract, Load, Transform) | Loads raw data into a store (often cloud data warehouse) then transforms there | When you have a scalable warehouse (e.g., Snowflake, BigQuery) and prefer in-warehouse transformations | Faster ingest and flexible transformations in SQL | Requires powerful storage/compute and good governance |
| CDC (Change Data Capture) | Streams only changes from source systems (inserts/updates/deletes) | For near-real-time syncs and replication between OLTP and analytics | Low-latency, efficient | Complexity around schema evolution and ordering |
| iPaaS / Integration Platform as a Service | Cloud platforms that connect SaaS apps, APIs and data flows | For SaaS-heavy environments and business-level integrations | Fast to set up, lots of prebuilt connectors | Pricing at scale and vendor lock-in concerns |
| Data Virtualization | Provides a query layer that joins multiple sources without copying data | When you need real-time unified view without centralizing data | Low storage overhead, near-real-time | Performance depends on sources; complex joins can be slow |
| Data Fabric / Mesh | Architectural approach combining automation, governance and domain ownership | For large organisations needing decentralized ownership + central governance | Scalability, domain autonomy | Requires cultural change and platform investment |
How modern organisations choose between ETL, ELT
Think in terms of three dimensions: latency (real-time vs batch), control & governance (centralised vs domain), and cost/scale (compute, storage and ops). A few heuristics:
- If you want analytics-ready tables built on cloud warehouses and easy SQL transformations: ELT.
- If you need robust pre-processing or complex enrichment before storage: ETL.
- If you need near-real-time replication from transactional databases to analytics: CDC.
- If you have many SaaS apps and want fast point-and-click connectors: iPaaS.
- If you want to avoid copying and join across sources on demand: data virtualization. https://www.ibm.com/think/topics/elt-vs-etl
Vendor snapshot — quick feature comparison
Below is a vendor-level snapshot to help you begin vendor shortlisting. Each product is briefly profiled to show strengths and ideal use cases. (Vendor names appear once in the table for clarity.)
| Vendor | Strength / specialty | Best for | Deployment model | Typical pricing model |
| Informatica | Enterprise-grade metadata, governance, broad connector set | Large enterprises with complex governance requirements | Cloud / Hybrid / On-prem | Subscription + enterprise licensing |
| Talend | Open-source roots, strong data quality tooling | Teams wanting open-source flexibility + enterprise features | Cloud / On-prem | Subscription, open-core options |
| MuleSoft | API-led, great for application integration and complex orchestrations | Organisations integrating many APIs and services | Cloud / Hybrid | Subscription (platform-based) |
| Apache NiFi | Flow-based visual data routing & transformation | Streaming, edge dataflows and event-driven pipelines | On-prem / Cloud (self-manage) | Open-source (support services optional) |
| Fivetran | Fully managed connectors for ELT, very low ops | Quick, reliable data ingestion to cloud warehouses | Cloud-managed | Consumption or per-connector subscription |
| Microsoft Azure Data Factory | Native integration with Azure services and hybrid connectivity | Organisations invested in Azure ecosystem | Cloud (Azure) | Consumption-based / pay-as-you-go |
Note: This snapshot is a starting point. Each vendor’s feature set, connector list and pricing change frequently — shortlist 2–3 vendors and run a short pilot before committing.
ETL vs ELT — practical considerations
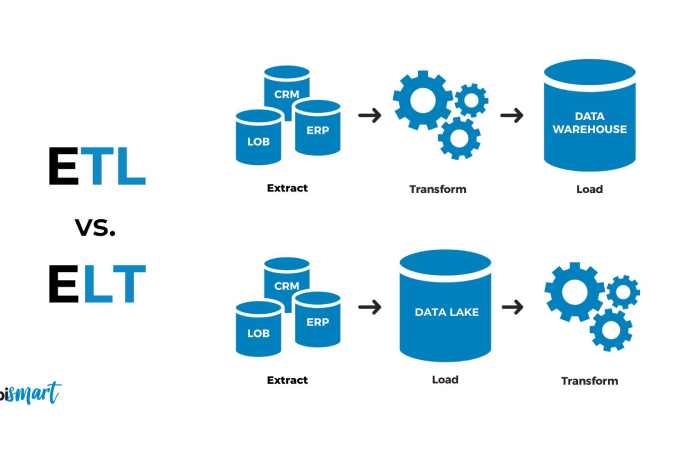
Both ETL and ELT move data; the difference is where the transformation happens.
- ETL (transform before load)
- Use when source systems are fragile, transformations are complex, or you must avoid storing raw PII.
- You control exactly what lands in the warehouse. This reduces downstream surprises at the cost of more operational complexity.
- Example: A payments team needs normalized, aggregated ledger entries with enriched merchant metadata before analytics teams can touch them.
- ELT (load then transform)
- Use when you have a powerful cloud warehouse and want flexible, reproducible SQL transformations.
- Easier to store raw data for audit and reprocessing. Transformations are often done with tools like dbt.
- Example: Product analytics team loads raw clickstream and transforms it in the warehouse to iterate rapidly on experiments.
Operational difference: ELT often lowers initial delivery time but can raise warehouse compute costs. ETL reduces compute costs in the warehouse but requires more middleware compute and operational support.
Schema evolution, and governance
Treat schema and ownership as first-class citizens:
- Data contract — A short document per dataset that records producer(s), consumer(s), schema (including types and nullability), SLAs, and who to call if something breaks.
- Schema registry — Use Avro/Protobuf/JSON Schema for event streams with versioning. For relational replication, track DDL changes with a small governance process.
- Backward/forward compatibility — Avoid breaking changes: add nullable fields first, deprecate old fields for a transition window, and automate compatibility tests.
- Enforce with CI — Tests should run on PRs that change schemas or transforms; a failing test blocks deployment.
- Data retention & minimisation — Only store what’s needed; mask or exclude sensitive attributes unless there’s a clear business need.
Concrete practice: require every new dataset to have a one-page data contract and a Slack channel for rapid troubleshooting. That channel becomes the fastest route to fix downstream issues.
Observability: metrics, lineage, and SLOs that actually help
Monitoring pipelines is different from monitoring apps. Focus on these signals:
- Freshness (latency): time between source event and dataset availability.
- Completeness: percent of expected batches/events received.
- Quality: validation pass rate (% records meeting schema/quality rules).
- Throughput & errors: records/sec and error events.
- Lineage: ability to trace any output value back to the original source and transformation step.
SRE-style SLO example:
- Freshness SLO: 95% of hourly datasets available within 30 minutes.
- Quality SLO: <0.1% records failing validation per dataset.
Instrument alerts to focus on SLO breaches, not every single error; too many alerts create noise and ignore real issues.
Implementation roadmap — expanded
This is a hands-on 10-step roadmap you can copy into a project plan.
- Business use case & metrics — Pick 1–2 high-value flows (e.g., monthly revenue reconciliation; real-time fraud scoring).
- Source inventory — For each source document format, update frequency, data owner, peak volume, and schema change risk.
- Define target architecture — Choose warehouse/lake/virtualization; define retention and access patterns.
- Map patterns to use cases — Decide ETL/ELT/CDC/iPaaS per source; document rationale.
- Shortlist vendors — Based on connectors, transformation model, governance, cost model.
- Pilot design — Same endpoints for all vendors: ingest X dataset, transform to Y model, measure latency and error rates.
- Run pilots — Time-boxed to 2–4 weeks; collect metrics and qualitative feedback from implementers.
- Evaluate — Score by connectors, latency, ops effort, cost estimate and security fit. Use 1–5 and weight by your priorities.
- Production rollout — Migrate flows, create runbooks, and onboard downstream consumers.
- Operate & iterate — Monitor SLOs, schedule quarterly cost reviews and a governance retrospective.
Cost modelling
- Connector pricing: some vendors charge per connector; others on volume. Model worst-case usage for the first year.
- Warehouse compute: ELT moves compute to the warehouse. Estimate both average and peak transform cost.
- Egress & staging: moving data between clouds or out of a managed platform can incur network and storage costs.
- Ops time: self-hosted systems need engineers to maintain and patch — budget headcount hours.
- Shadow costs: reprocessing failed jobs, incident debug time, and duplicated datasets all add up.
Practical tip: run a 90-day burn simulation during the pilot (artificially scale to expected peak) to see real pricing behavior.
Security & compliance
- Enforce encryption in transit and at rest.
- Integrate with SSO/IdP and role-based access controls (RBAC).
- Maintain audit logs for data access and pipeline changes.
- Provide data masking/tokenization for PII pipelines.
- If needed, use region-specific storage and processing to meet data residency laws.
Checklist: require SOC 2 or equivalent vendor attestations for cloud vendors and perform a security review for any new connector.
Common pitfalls and how to avoid them
- Pilot paralysis — Pilots that never pick winners. Fix: strict timeboxes and success criteria.
- One-off scripts — ad-hoc integrations that become hard to maintain. Fix: create templates and reusable connectors.
- No data ownership — nobody knows who to call. Fix: require dataset owner in the data contract.
- Ignoring downstream consumers — changes break dashboards. Fix: involve consumers during schema design and use deprecation windows.
- Cost explosion — transformations in warehouse become expensive. Fix: cost monitoring and limit heavy transforms during peak hours.
FAQ
Q: Should we centralise or decentralise integration?
A: Mix both. Central platform and standards, with domain teams owning dataset production and domain-specific transforms.
Q: How do we handle GDPR/PII?
A: Minimise copying of PII. Use masking/tokenisation. Only allow datasets with PII to be created with explicit governance and purpose.
Q: How long before ROI?
A: For a focused pilot (billing reconciliation, monthly close), you can show ROI in 2–3 months by reducing manual work and errors.



